使用BERT半年多了,一直用的是Huggingface的pytorch代码,最近毕业抽空跟着Google官方Tensorflow代码敲了一遍,为了能够做到深入理解并复现,在这里详细分析BERT的官方代码。争取做到,能够理解后复现出来。上车🚗🚗🚗
tokenization.py
这是对BERT输入进行分词的代码部分,我们先绘制出 tokenization.py 文件的结构,然后逐个函数逐行分析。
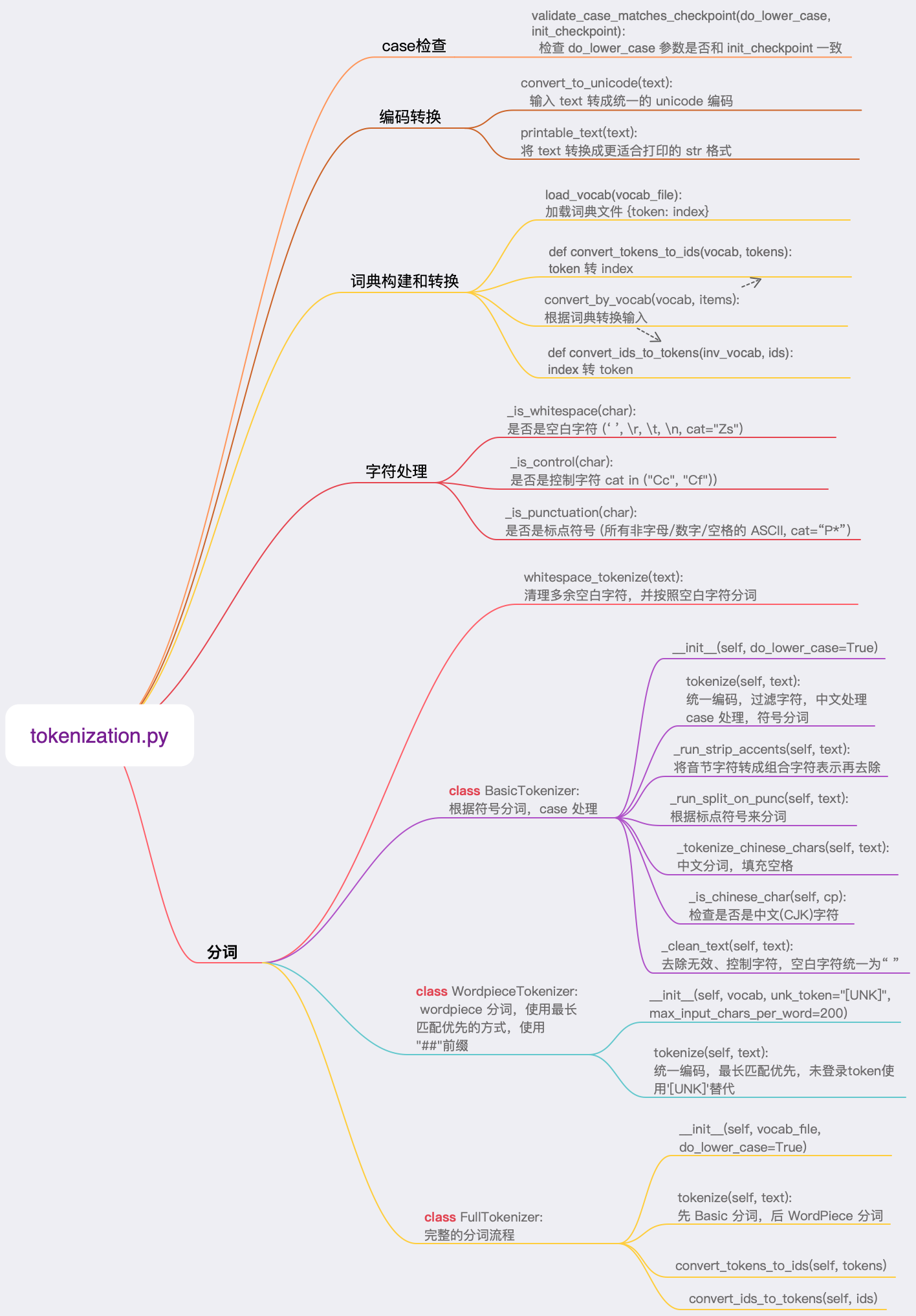
Bert 的分词使用 FullTokenizer,包括两部分:
- 使用 BasicTokenizer 根据符号分词,字母大小写处理,得到 tokens
- 统一 unicode 编码,并去除无效字符、控制字符,统一空白字符
- 中文分词支持
- 处理大小写,去除音节符
- 根据符号分词
- 空格分词
- 使用 WordpieceTokenizer 分词,得到 sub_tokens
- 使用 wordpiece 方式分词,使用最长匹配优先的方式,使用 “##”前缀
补充参考:*
unicodedata.category() 的返回值可以参考 https://www.compart.com/en/unicode/category
ASCII码表可以参考 https://zh.wikipedia.org/wiki/Unicode字符列表#基本拉丁字母
case检查
validate_case_matches_checkpoint
这个函数的目的是检查传入参数 do_lower_case(是否大小写敏感) 和 要加载的模型 是是否匹配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34def validate_case_matches_checkpoint(do_lower_case, init_checkpoint):
if not init_checkpoint: # 输入合法性判断
return
# 使用懒惰模式来匹配模型的名称
# 比如:init_checkpoint = /root/bert/uncased_L-12_H-768_A-12/bert_model.ckpt
# 匹配后 model_name = uncased_L-12_H-768_A-12
m = re.match("^.*?([A-Za-z0-9_-]+)/bert_model.ckpt", init_checkpoint)
if m is None:
return
model_name = m.group(1)
# Google 提供的预训练好的模型名称集合
lower_models = [
"uncased_L-24_H-1024_A-16", "uncased_L-12_H-768_A-12",
"multilingual_L-12_H-768_A-12", "chinese_L-12_H-768_A-12"
]
cased_models = [
"cased_L-12_H-768_A-12", "cased_L-24_H-1024_A-16",
"multi_cased_L-12_H-768_A-12"
]
is_bad_config = False
# 要加载的模型大小写不敏感,而传入的参数是大小写敏感
if model_name in lower_models and not do_lower_case:
is_bad_config = True
...
# 要加载的模型大小写敏感,而传入的参数是大小写不敏感
if model_name in cased_models and do_lower_case:
is_bad_config = True
...
# 不一致就抛异常
if is_bad_config:
raise ValueError(...)
编码转换
convert_to_unicode
将输入 text 转成统一的 unicode 编码。这里需要区分:
python3 有两种表示字符序列的类型:bytes 和 str。前者的实例包含原始的8位值;后者的实例包含Unicode字符。
python2 中也有两种表示字符序列的类型,分别叫做 str 和 unicode。与 python3 不同的是,str 的实例包含原始的8位值,而 unicode 的实例才包含 Unicode 字符。
python 中,使用 unicode 类型作为编码的基础类型:
str ——(decode)—-> unicode ——(encode)—->str
- Unicode 是「字符集」UTF-8 是「编码规则」
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def convert_to_unicode(text):
"""Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
if six.PY3:
if isinstance(text, str):
return text
elif isinstance(text, bytes):
return text.decode("utf-8", "ignore")
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
elif six.PY2:
if isinstance(text, str):
return text.decode("utf-8", "ignore")
elif isinstance(text, unicode):
return text
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
else:
raise ValueError("Not running on Python2 or Python 3?")
printable_text
将 text 转换成更适合打印的 str 格式,供 print / tf.logging 这样的函数使用。这些函数的指定输入格式都是 str 格式,格式之间的差异见convert_to_unicode 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def printable_text(text):
"""Returns text encoded in a way suitable for print or `tf.logging`."""
# These functions want `str` for both Python2 and Python3, but in one case
# it's a Unicode string and in the other it's a byte string.
if six.PY3:
if isinstance(text, str):
return text
elif isinstance(text, bytes):
return text.decode("utf-8", "ignore") # **de**code
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
elif six.PY2:
if isinstance(text, str):
return text
elif isinstance(text, unicode):
return text.encode("utf-8") # **en**code
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
else:
raise ValueError("Not running on Python2 or Python 3?")
词典构建和转换
load_vocab
加载词典文件,存入到 OrderedDict {token: index}
1
2
3
4
5
6
7
8
9
10
11
12
13def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
vocab = collections.OrderedDict()
index = 0
with tf.gfile.GFile(vocab_file, "r") as reader:
while True:
token = convert_to_unicode(reader.readline())
if not token: # 当 token == '' 时候
break
token = token.strip()
vocab[token] = index
index += 1
return vocab # uncased_L-12_H-768_A-12模型的 len(vocab)=30522convert_by_vocab / convert_tokens_to_ids / convert_ids_to_tokens
根据此词表,实现 token 和 id 之间的互转
1
2
3
4
5
6
7
8
9
10
11def convert_by_vocab(vocab, items):
output = []
for item in items:
output.append(vocab[item])
return output
def convert_tokens_to_ids(vocab, tokens): # vocab
return convert_by_vocab(vocab, tokens)
def convert_ids_to_tokens(inv_vocab, ids): # inv_vocab!
return convert_by_vocab(inv_vocab, ids)
字符处理
_is_whitespace / _is_control / _is_punctuation
是否是 空白符、控制符、标点符1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def _is_whitespace(char):
if char == " " or char == "\t" or char == "\n" or char == "\r":
return True
cat = unicodedata.category(char)
if cat == "Zs": # "Zs" 表示 Space Separator
return True
return False
def _is_control(char):
if char == "\t" or char == "\n" or char == "\r":
return False
cat = unicodedata.category(char)
if cat in ("Cc", "Cf"):
return True
return False
def _is_punctuation(char):
cp = ord(char)
# 所有非 字母/数字 的ASCII字符,**注意:没有包括空格符号**
if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or
(cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
return True
# 所有 unicode 中分类为 punctuation 的字符
cat = unicodedata.category(char)
if cat.startswith("P"):
return True
return False
分词
whitespace_tokenize
清理text前后的空格类符号,然后根据空格分词
1
2
3
4
5
6def whitespace_tokenize(text):
text = text.strip()
if not text:
return []
tokens = text.split()
return tokensBasicTokenizer 类
实现简单的分词功能:根据符号分词,字母大小写处理。
流程:统一 unicode 编码,并去除无效字符、控制字符,统一空白字符 -> 中文分词支持 -> 去除多余空格 -> 处理大小写,去除音节符 -> 根据符号分词 -> 空格分词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97class BasicTokenizer(object):
def __init__(self, do_lower_case=True):
self.do_lower_case = do_lower_case
# 统一编码,过滤字符,中文处理,case 处理,符号分词
def tokenize(self, text):
# 统一为 unicode 编码,并去除无效字符、控制字符,将空白字符统一为单个空格
text = convert_to_unicode(text)
text = self._clean_text(text)
text = self._tokenize_chinese_chars(text) # 中文支持
orig_tokens = whitespace_tokenize(text) # 去除多余空白符
split_tokens = []
for token in orig_tokens:
if self.do_lower_case: # 大小写处理
token = token.lower()
token = self._run_strip_accents(token) # 去除音节符
split_tokens.extend(self._run_split_on_punc(token)) # 根据符号分词
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
# 将音节字符转成组合字符表示再去除
def _run_strip_accents(self, text):
"""Strips accents from a piece of text."""
# 在Unicode中,某些字符能够用多个合法的编码表示
# normalize() 第一个参数指定字符串标准化的方式
# NFC表示字符应该是整体组成(比如可能的话就使用单一编码),如 'fi'
# 而NFD表示字符应该分解为多个组合字符表示,如 'fi'
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
if cat == "Mn": # Nonspacing Mark
continue
output.append(char)
return "".join(output)
# 根据标点符来分词
# 例如:"anti-labor" => ['anti', '-', 'labor']
def _run_split_on_punc(self, text):
"""Splits punctuation on a piece of text."""
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char]) # 标点也存
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
def _tokenize_chinese_chars(self, text):
"""Adds whitespace around any CJK character."""
# CJK: Chinese Japanese Korean
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ") # 多余的空格通过后面的 whitespace_tokenize 流程去除
else:
output.append(char)
return "".join(output)
def _is_chinese_char(self, cp):
"""Checks whether CP is the codepoint of a CJK character."""
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
if ((cp >= 0x4E00 and cp <= 0x9FFF) or ...: #
return True
return False
# 去除无效字符、控制字符,将空白字符统一为单个空格
def _clean_text(self, text):
"""Performs invalid character removal and whitespace cleanup on text."""
output = []
for char in text:
cp = ord(char)
# 0 表示 NULL
# invalid character 会转换成 Unicode 的REPLACEMENT CHARACTER(0xFFFD)
if cp == 0 or cp == 0xfffd or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)WordpieceTokenizer 类
使用 wordpiece 方式分词,使用最长匹配优先的方式,使用 “##”前缀。
这里有个问题:未登录词会不会影响将来 answer 的定位??我的回答:不会,没找的词替换为 ‘[UNK]’ 后还是一个position 的占位,还是对齐的。在预测阶段如果要输出,输出对应位置原来的 token。这一处理可以参见 run_squad.py 中的 get_final_text()。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49class WordpieceTokenizer(object):
"""Runs WordPiece tokenziation."""
def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
self.vocab = vocab
self.unk_token = unk_token
self.max_input_chars_per_word = max_input_chars_per_word
# 统一编码,最长匹配优先,未登录token使用'[UNK]'替代
def tokenize(self, text):
"""greedy **longest**-match-first
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
"""
text = convert_to_unicode(text)
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False # 是否是未登录token
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1 # **longest**-match-first
if cur_substr is None: # 出现未登录token,终止流程
is_bad = True
break
sub_tokens.append(cur_substr)
start = end # 寻找下一个 token
if is_bad: # 未登录token使用'[UNK]'替代
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokensFullTokenizerr 类
流程:text -> 使用 BasicTokenizer 根据符号分词,字母大小写处理,得到 tokens -> 使用 WordpieceTokenizer 分词,得到 sub_tokens
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class FullTokenizer(object):
"""Runs end-to-end tokenziation."""
def __init__(self, vocab_file, do_lower_case=True):
self.vocab = load_vocab(vocab_file) # {token: index}
self.inv_vocab = {v: k for k, v in self.vocab.items()} # {index: token}
self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
def tokenize(self, text):
split_tokens = []
for token in self.basic_tokenizer.tokenize(text):
for sub_token in self.wordpiece_tokenizer.tokenize(token):
split_tokens.append(sub_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
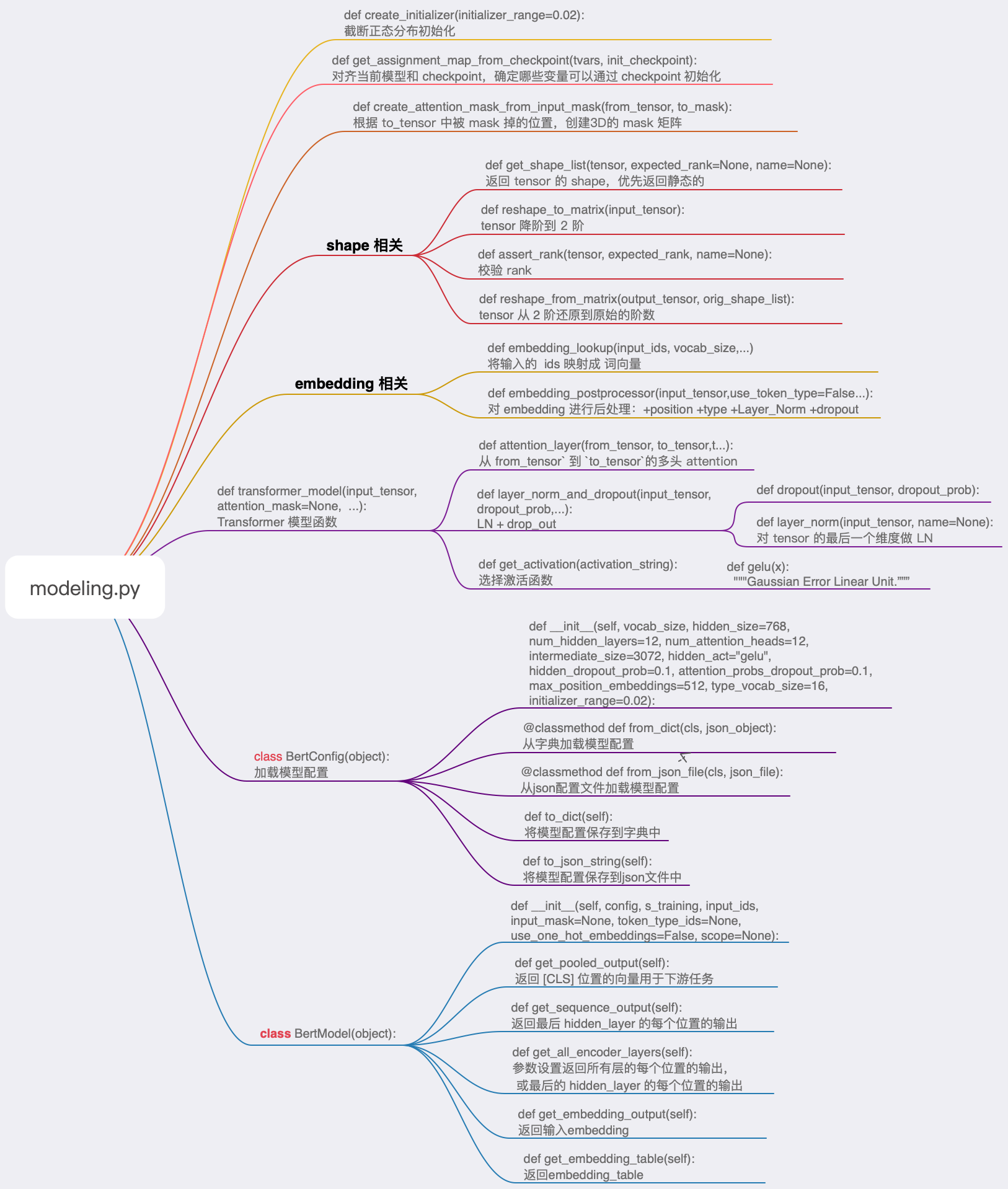
modeling.py
这是对BERT模型的代码部分,我们先绘制出 modeling.py 文件的结构,然后逐个函数逐行分析。
create_initializer
从截断的正态分布中输出随机值。生成的值服从具有指定平均值和标准偏差的正态分布,如果生成的值大于平均值2个标准偏差的值则丢弃重选。
1
2
3def create_initializer(initializer_range=0.02):
"""Creates a `truncated_normal_initializer` with the given range."""
return tf.truncated_normal_initializer(stddev=initializer_range)get_assignment_map_from_checkpoint
对齐当前模型和 checkpoint,确定哪些变量可以通过 checkpoint 初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def get_assignment_map_from_checkpoint(tvars, init_checkpoint):
"""Compute the union of the current variables and checkpoint variables."""
assignment_map = {}
initialized_variable_names = {}
# Returns dict of all trainable variables in the model.
name_to_variable = collections.OrderedDict()
for var in tvars:
name = var.name # 例 'bert/embeddings/word_embeddings:0'
m = re.match("^(.*):\\d+$$", name)
if m is not None:
name = m.group(1) # 例 'bert/embeddings/word_embeddings'
name_to_variable[name] = var
# Returns list of all variables in the checkpoint.
init_vars = tf.train.list_variables(init_checkpoint)
# 查找那些模型中的参数可以使用 checkpoint 初始化
assignment_map = collections.OrderedDict()
for x in init_vars:
(name, var) = (x[0], x[1])
if name not in name_to_variable:
continue
assignment_map[name] = name
initialized_variable_names[name] = 1
initialized_variable_names[name + ":0"] = 1
return (assignment_map, initialized_variable_names)create_attention_mask_from_input_mask
这个函数有点绕。我们不用管 batch_size 可能更容易理解一些。
对于一个 from_seq_length 的输入,我们从它的每个位置去 attend 目标序列中的没有被 mask 掉的位置。
[1, to_seq_length] * [from_seq_length, 1] => [from_seq_length, to_seq_length]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def create_attention_mask_from_input_mask(from_tensor, to_mask):
"""Create 3D attention mask from a 2D tensor mask.
Args:
from_tensor: 2D or 3D Tensor of shape [batch_size, from_seq_length, ...].
to_mask: int32 Tensor of shape [batch_size, to_seq_length].
Returns:
float Tensor of shape [batch_size, from_seq_length, to_seq_length].
"""
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_shape = get_shape_list(to_mask, expected_rank=2)
to_seq_length = to_shape[1]
to_mask = tf.cast(
tf.reshape(to_mask, [batch_size, 1, to_seq_length]), tf.float32)
# We don't actually care if we attend *from* padding tokens (only *to* padding)
# tokens so we create a tensor of all ones.
broadcast_ones = tf.ones(
shape=[batch_size, from_seq_length, 1], dtype=tf.float32) # 从 from_seq 的每个位置去 attend to_seq
# Here we broadcast along two dimensions to create the mask.
mask = broadcast_ones * to_mask
return mask
shape 相关
get_shape_list
返回 tensor 的维度信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def get_shape_list(tensor, expected_rank=None, name=None):
"""Returns a list of the shape of tensor, preferring static dimensions."""
...
shape = tensor.shape.as_list()
non_static_indexes = []
for (index, dim) in enumerate(shape):
if dim is None: # 动态维度
non_static_indexes.append(index)
if not non_static_indexes: # 不存在动态维度
return shape
# 动态维度根据实际 tensor 的对应维度来填充
dyn_shape = tf.shape(tensor)
for index in non_static_indexes:
shape[index] = dyn_shape[index]
return shapereshape_to_matrix / reshape_from_matrix
reshape_to_matrix 将超过2阶的 tensor 转成2阶,reshape_from_matrix 执行相反操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def reshape_to_matrix(input_tensor):
"""Reshapes a >= rank 2 tensor to a rank 2 tensor (i.e., a matrix)."""
ndims = input_tensor.shape.ndims
...
if ndims == 2:
return input_tensor
width = input_tensor.shape[-1]
output_tensor = tf.reshape(input_tensor, [-1, width])
return output_tensor
def reshape_from_matrix(output_tensor, orig_shape_list):
"""Reshapes a rank 2 tensor back to its original rank >= 2 tensor."""
if len(orig_shape_list) == 2:
return output_tensor
output_shape = get_shape_list(output_tensor)
orig_dims = orig_shape_list[0:-1]
width = output_shape[-1]
return tf.reshape(output_tensor, orig_dims + [width])assert_rank
rank 校验
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def assert_rank(tensor, expected_rank, name=None):
"""Raises an exception if the tensor rank is not of the expected rank."""
...
expected_rank_dict = {}
# 只期望一个 rank
if isinstance(expected_rank, six.integer_types):
expected_rank_dict[expected_rank] = True
else:
# 输入 expected_rank 为list[],存在多个期望的 rank
for x in expected_rank:
expected_rank_dict[x] = True
actual_rank = tensor.shape.ndims # tensor 实际的 rank
if actual_rank not in expected_rank_dict:
raise ValueError(...)
embedding 相关
embedding_lookup
将输入的 ids 映射成 词向量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def embedding_lookup(input_ids, # int32 Tenso: [batch_size, seq_length]
vocab_size,
embedding_size=128, # BERT_base 中 768
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
# 默认输入3阶 [batch_size, seq_length, num_inputs]
# 2阶输入[batch_size, seq_length] 扩展为 [batch_size, seq_length, num_inputs=1]
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1]) # [batch_size, seq_length, num_inputs=1]
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
flat_input_ids = tf.reshape(input_ids, [-1]) # [batch_size*seq_length*num_inputs,]
# 小 vocabulary 时候 use_one_hot_embeddings 更快
# 大 vocabulary 时候 tf.gather 更快
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size) # [batch_size*seq_length*num_inputs, vocab_size]
output = tf.matmul(one_hot_input_ids, embedding_table) # [batch_size*seq_length*num_inputs, embedding_size]
else:
output = tf.gather(embedding_table, flat_input_ids) # [batch_size*seq_length*num_inputs, embedding_size]
input_shape = get_shape_list(input_ids)
# # [batch_size, seq_length, num_inputs*embedding_size]
output = tf.reshape(output, input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)embedding_postprocessor
对 embedding 进行后处理:+ position_emb + type/segment_emb + Layer_Norm + dropout
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55def embedding_postprocessor(input_tensor, # [batch_size, seq_length, embedding_size]
use_token_type=False,
token_type_ids=None, # [batch_size, seq_length]
token_type_vocab_size=16, # 最多16种type
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512, # 序列最大可用长度
dropout_prob=0.1):
input_shape = get_shape_list(input_tensor, expected_rank=3) # [batch_size, seq_length, embedding_size]
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor
if use_token_type:
... # 输入合法性判断
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# 小 vocabulary 时候 use_one_hot_embeddings 更快
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings # 直接按位加
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings) # 输入合法性判断
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# 截取 [0, 1, ... seq_length-1] 区间的 embedding_table,更快
position_embeddings = tf.slice(full_position_embeddings, [0, 0], [seq_length, -1])
num_dims = len(output.shape.as_list())
# Only the last two dimensions are relevant (`seq_length` and `width`), so
# we broadcast among the first dimensions —— the batch size.
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings # 直接按位加
output = layer_norm_and_dropout(output, dropout_prob)
return output
Transformer 模型
transformer_model
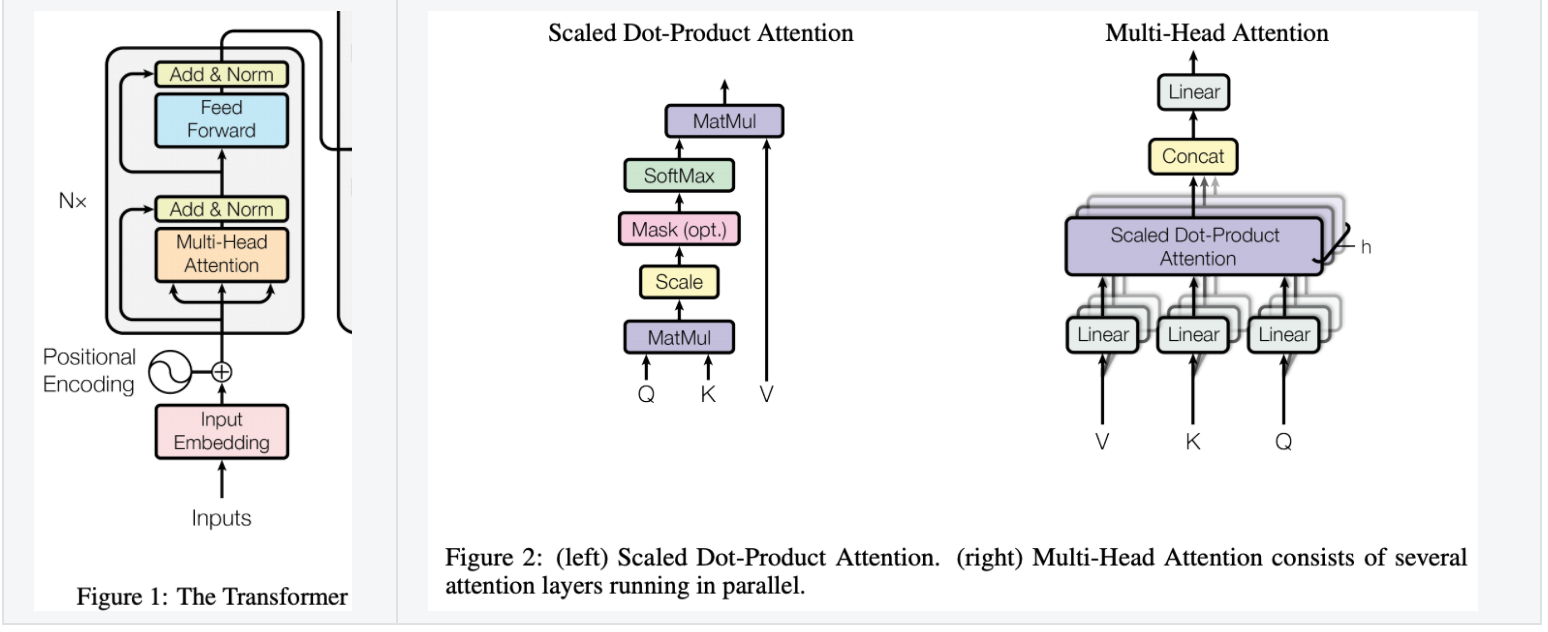
Scaled Dot-Product Attention
queries and keys of dimension ,values of dimension
queries, keys and values are packed together into matrices , and .
why scale the product by : for large values of , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.
Multi-Head Attention
Position-wise Feed-Forward Networks
- Another way of describing this is as two convolutions with kernel size 1
详细的 Transformer 相关的可以参照原论文和代码实现。
1 | def transformer_model(input_tensor, # [batch_size, seq_length, hidden_size] |
attention_layer
多头 attention 的计算,实际上多头机制通过矩阵的transposes 和 reshape 方式来并行实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None, # Activation function for the query transform.
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None, # 2D input 才需要
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
In practice, the multi-headed attention are done with transposes and
reshapes rather than actual separate tensors."""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
...
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
from_tensor_2d = reshape_to_matrix(from_tensor) # [B*F, width]
to_tensor_2d = reshape_to_matrix(to_tensor) # [B*T, width]
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d, #
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d, #
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# `query_layer` = [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Dot product between "query" and "key" to get the raw attention scores.
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# 将被 mask 掉的地方的 attention 值设置为很小的负数,这样在做 softmax 后,
# 这些位置的概率为 0.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layerlayer_norm_and_dropout
这个函数组没啥好说的,如代码所示。如果这个都看不懂,别继续看了。
参考论文 https://arxiv.org/abs/1607.06450
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def dropout(input_tensor, dropout_prob): # NOT of *keeping* a dimension as in `tf.nn.dropout`
if dropout_prob is None or dropout_prob == 0.0:
return input_tensor
output = tf.nn.dropout(input_tensor, 1.0 - dropout_prob)
return output
def layer_norm(input_tensor, name=None):
"""Run layer normalization on the last dimension of the tensor."""
return tf.contrib.layers.layer_norm(
inputs=input_tensor, begin_norm_axis=-1, begin_params_axis=-1, scope=name)
def layer_norm_and_dropout(input_tensor, dropout_prob, name=None):
"""Runs layer normalization followed by dropout."""
output_tensor = layer_norm(input_tensor, name)
output_tensor = dropout(output_tensor, dropout_prob)
return output_tensorget_activation
根据名称返回对应的激活函数,支持 “linear” / “relu” / “gelu” / “tanh”
1
2
3
4
5
6def get_activation(activation_string):
"""Maps a string to a Python function, e.g., "relu" => `tf.nn.relu`."""
...
act = activation_string.lower()
if act == "linear":
...gelu
1
2
3
4
5
6
7def gelu(x):
"""Gaussian Error Linear Unit.
Original paper: https://arxiv.org/abs/1606.08415
"""
cdf = 0.5 * (1.0 + tf.tanh(
(np.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3)))))
return x * cdfBertConfig类
关键配置: (L=12, H=768, A=12, Total Parameters=110M)
(L=24, H=1024, A=16, Total Parameters=340M).
L: num_hidden_layers, H: hidden_size, A: num_attention_heads
代码运行逻辑:
BertConfig.from_json_file(FLAGS.bert_config_file) —> cls.from_dict(json.loads(text)) ,在 from_dict 函数中完成 BertConfig 实例化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42class BertConfig(object):
"""Configuration for `BertModel`."""
def __init__(self, vocab_size, hidden_size=768, num_hidden_layers=12, num_attention_heads=12,
intermediate_size=3072, hidden_act="gelu", hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1, max_position_embeddings=512, type_vocab_size=16,
initializer_range=0.02):
"""...
intermediate_size: The size of the "intermediate" (i.e., feed-forward)
layer in the Transformer encoder.
...
max_position_embeddings: The maximum sequence length that this model might
ever be used with. Typically set this to something large just in case
(e.g., 512 or 1024 or 2048).
...
"""
self.vocab_size = vocab_size
...
def from_dict(cls, json_object):
"""Constructs a `BertConfig` from a Python dictionary of parameters."""
config = BertConfig(vocab_size=None)
for (key, value) in six.iteritems(json_object):
config.__dict__[key] = value
return config
def from_json_file(cls, json_file): # 例: json_file='/root/bert/uncased_L-12_H-768_A-12/bert_config.json'
"""Constructs a `BertConfig` from a json file of parameters."""
with tf.gfile.GFile(json_file, "r") as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def to_dict(self): # 将对象转成字典
"""Serializes this instance to a Python dictionary."""
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self): # 将对象转成json
"""Serializes this instance to a JSON string."""
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"BertModel类
构建输入:
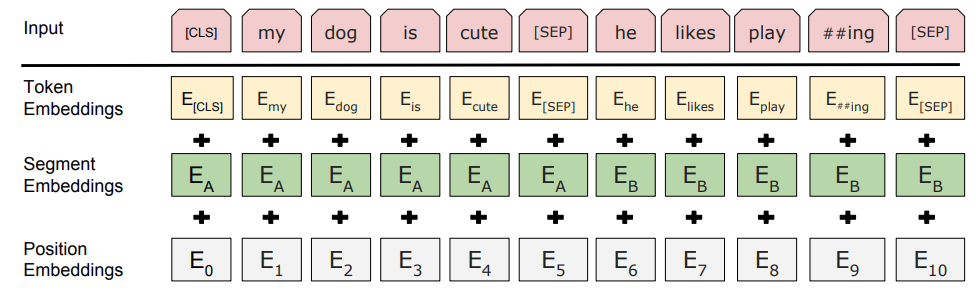
构造函数的代码逻辑:
获取模型配置 -> 根据是否训练设置dropout -> 检查mask和type -> 计算输入embedding -> # 使用多层 Transformer Block 处理 -> Transformer的输出用于下游任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90class BertModel(object):
"""BERT model ("Bidirectional Encoder Representations from Transformers").
Example usage:
```python
# Already been converted into WordPiece token ids
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
model = modeling.BertModel(config=config, is_training=True,
input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
label_embeddings = tf.get_variable(...)
pooled_output = model.get_pooled_output()
logits = tf.matmul(pooled_output, label_embeddings)
...
```
"""
def __init__(self,
config, # `BertConfig` 对象
is_training, # bool. 控制是否使用 dropout
input_ids, # int32 Tensor: [batch_size, seq_length]
input_mask=None, # (optional)int32 Tensor: [batch_size, seq_length]
token_type_ids=None, # (optional)int32 Tensor: [batch_size, seq_length]
use_one_hot_embeddings=False, # word embeddings 使用 one-hot embeddings 还是 tf.embedding_lookup()
scope=None):
config = copy.deepcopy(config)
if not is_training: # eval 模式不使用 dropout
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2) # [12, 384]
batch_size = input_shape[0]
seq_length = input_shape[1]
# 检查 mask 和 type
if input_mask is None: # 没有指定 mask 就认为所有位置都是真实tokens,全部需要 attend
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None: # 没有指定 type 就把整个输入当作一个 type/segment
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
# 计算输入embedding
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
(self.embedding_output, self.embedding_table) = embedding_lookup(...)
# word embeddings + positional embeddings + token type embeddings
# 然后 layer normalize & perform dropout.
self.embedding_output = embedding_postprocessor(...)
# 使用多层 Transformer Block 处理
with tf.variable_scope("encoder"):
# 计算在 attention 矩阵中要 mask 掉的位置
attention_mask = create_attention_mask_from_input_mask(input_ids, input_mask)
# Run the stacked transformer.
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(...)
# Transformer的输出用于下游任务
self.sequence_output = self.all_encoder_layers[-1] # 最后的 hidden_layer
# 使用最后hidden_layer 的 [cls] 位置的输出来完成 classification 的下游任务
with tf.variable_scope("pooler"):
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
# 返回 [CLS] 位置的向量用于下游任务
def get_pooled_output(self):
return self.pooled_output
# 返回最后的 hidden_layer 的每个位置的输出
def get_sequence_output(self):
"""Gets final hidden layer of encoder: [batch_size, seq_length, hidden_size]"""
return self.sequence_output
# 参数设置返回所有层的每个位置的输出,或最后的 hidden_layer 的每个位置的输出
def get_all_encoder_layers(self):
return self.all_encoder_layers
# 返回输入embedding
def get_embedding_output(self):
return self.embedding_output
# 返回embedding_table
def get_embedding_table(self):
return self.embedding_table
optimization.py

create_optimizer
BERT 论文里:We use Adam with learning rate of 1e-4, = 0.9, = 0.999, L2 weight decay of 0.01, learning rate warm-up over the first 10,000 steps, and linear decay of the learning rate.
该函数的流程为:计算学习率(先 warm_up 后 线性衰减) -> 创建优化器 -> 计算梯度 -> 裁剪梯度 -> 更新参数和global_step
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, use_tpu):
"""Creates an optimizer training op."""
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=init_lr, shape=[], dtype=tf.float32)
# 线性衰减学习率 `power` = 1.0
# global_step = min(global_step, decay_steps)
# decayed_learning_rate = (learning_rate - end_learning_rate) *
# (1 - global_step / decay_steps) ^ (power) +
# end_learning_rate
learning_rate = tf.train.polynomial_decay(...)
# Implements linear warmup. I.e., if global_step < num_warmup_steps, the
# learning rate will be `global_step/num_warmup_steps * init_lr`.
if num_warmup_steps:
global_steps_int = tf.cast(global_step, tf.int32)
warmup_steps_int = tf.constant(num_warmup_steps, dtype=tf.int32)
global_steps_float = tf.cast(global_steps_int, tf.float32)
warmup_steps_float = tf.cast(warmup_steps_int, tf.float32)
warmup_percent_done = global_steps_float / warmup_steps_float
warmup_learning_rate = init_lr * warmup_percent_done
# 根据 global_steps 选择是 warmup 阶段 还是 decay 阶段
is_warmup = tf.cast(global_steps_int < warmup_steps_int, tf.float32)
learning_rate = (
(1.0 - is_warmup) * learning_rate + is_warmup * warmup_learning_rate)
# 推荐在 fine-tune 阶段使用这个 optimizer (保持一致性)
# Adam m/v variables **不** 从 init_checkpoint 加载
optimizer = AdamWeightDecayOptimizer(...)
# CrossShardOptimizer 与本地训练不兼容,要在本地和 Cloud TPU 上运行相同代码,请添加:
if use_tpu:
# 这个接口似乎有 bug,目前官方文档中已经 404
# 使用 allreduce 聚合梯度并将结果广播到各个分片(每个 TPU 核)
optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer)
# 对可训练变量计算梯度
tvars = tf.trainable_variables()
grads = tf.gradients(loss, tvars)
# 梯度截断使用 clip_by_global_norm(t_list, clip_norm, ...)
# global_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))
# t_list[i] * clip_norm / max(global_norm, clip_norm)
# 参考 http://arxiv.org/pdf/1211.5063.pdf
(grads, _) = tf.clip_by_global_norm(grads, clip_norm=1.0)
train_op = optimizer.apply_gradients(
zip(grads, tvars), global_step=global_step)
# 通常在 apply_gradients 中更新 global_step,我们在这里更新
new_global_step = global_step + 1
train_op = tf.group(train_op, [global_step.assign(new_global_step)])
return train_opAdamWeightDecayOptimizer
Adam 优化器:
Initialization:
update rule:
- 是一阶动量, 是二阶动量, 是梯度
Adam 的 weight decay:bert训练采用的优化方法就是adamw,对除了layernorm,bias项之外的模型参数做weight decay。
- 将权重的平方和加到损失函数中不是正确的 Adam 的 weight decay。
- 这种方式等价于 SGD 的 L2 regularization。
可以参见ICLR 2019这篇文章 https://arxiv.org/pdf/1711.05101.pdf 或者 通俗版 https://zhuanlan.zhihu.com/p/63982470
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79class AdamWeightDecayOptimizer(tf.train.Optimizer):
"""A basic Adam optimizer that includes "correct" L2 weight decay."""
def __init__(self,
learning_rate,
weight_decay_rate=0.0,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-6,
exclude_from_weight_decay=None,
name="AdamWeightDecayOptimizer"):
"""Constructs a AdamWeightDecayOptimizer."""
super(AdamWeightDecayOptimizer, self).__init__(False, name)
self.learning_rate = learning_rate
...
# 更新参数
def apply_gradients(self, grads_and_vars, global_step=None, name=None):
"""See base class."""
assignments = []
for (grad, param) in grads_and_vars:
if grad is None or param is None:
continue
param_name = self._get_variable_name(param.name)
# 一阶动量
m = tf.get_variable(
name=param_name + "/adam_m",
shape=param.shape.as_list(),
dtype=tf.float32,
trainable=False,
initializer=tf.zeros_initializer())
# 二阶动量
v = tf.get_variable(
name=param_name + "/adam_v",
shape=param.shape.as_list(),
dtype=tf.float32,
trainable=False,
initializer=tf.zeros_initializer())
# Standard Adam update.
next_m = (
tf.multiply(self.beta_1, m) + tf.multiply(1.0 - self.beta_1, grad))
next_v = (
tf.multiply(self.beta_2, v) + tf.multiply(1.0 - self.beta_2,
tf.square(grad)))
update = next_m / (tf.sqrt(next_v) + self.epsilon)
# Adam 的正确 weight decay 方式
if self._do_use_weight_decay(param_name):
update += self.weight_decay_rate * param
update_with_lr = self.learning_rate * update
next_param = param - update_with_lr
assignments.extend(
[param.assign(next_param),
m.assign(next_m),
v.assign(next_v)])
return tf.group(*assignments, name=name)
def _do_use_weight_decay(self, param_name):
"""Whether to use L2 weight decay for `param_name`."""
if not self.weight_decay_rate:
return False
if self.exclude_from_weight_decay: # 本例中 ['LayerNorm', 'layer_norm', 'bias']
for r in self.exclude_from_weight_decay:
if re.search(r, param_name) is not None:
return False
return True
def _get_variable_name(self, param_name):
"""Get the variable name from the tensor name."""
m = re.match("^(.*):\\d+$$", param_name)
if m is not None:
param_name = m.group(1)
return param_name
run_squad.py
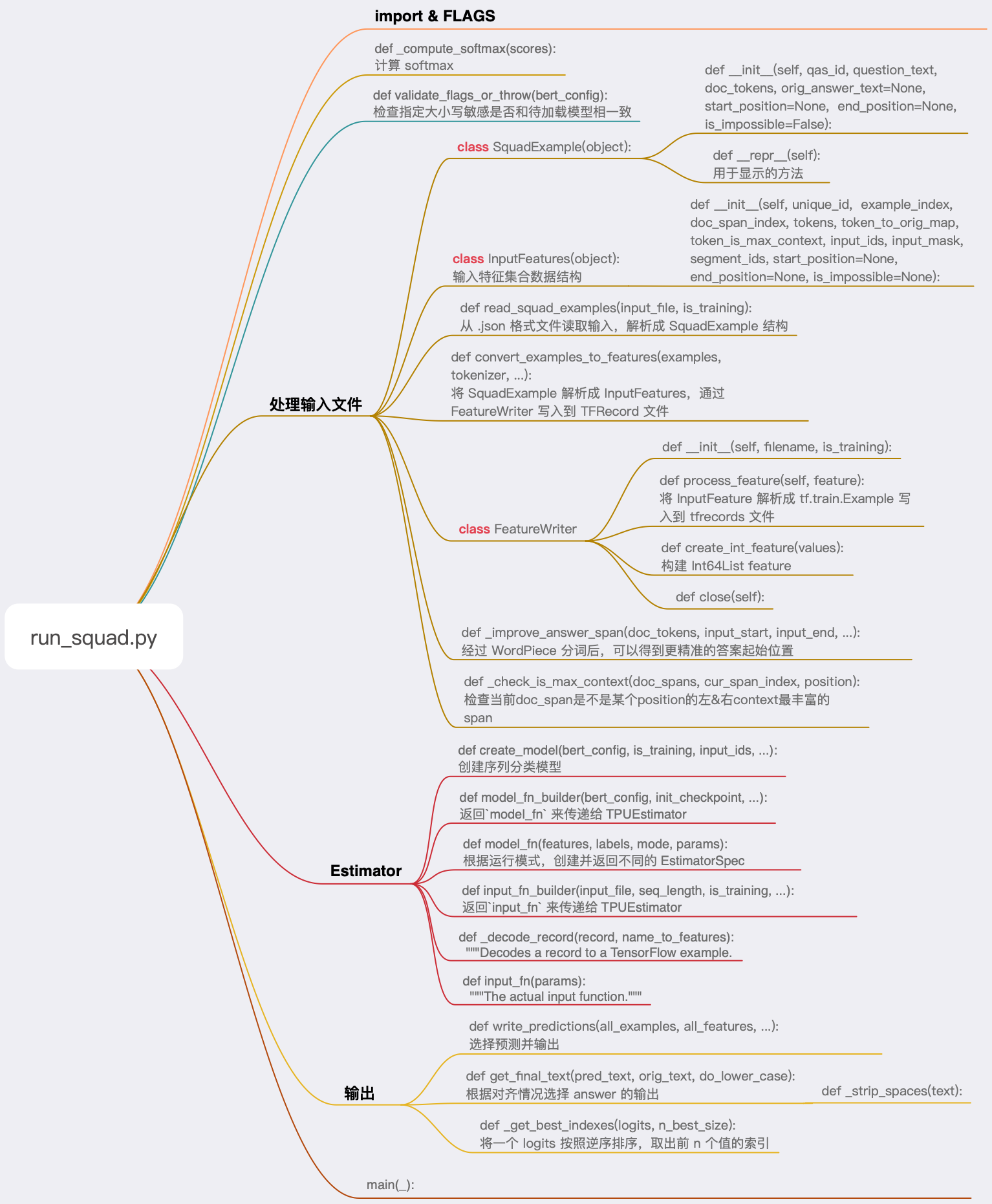
这是 Bert 运行 Squad 任务的主程序,使用了 Estimator 高级 API 实现,可以参考 https://www.tensorflow.org/guide/custom_estimators 详细了解特性和实现。
要根据预创建的 Estimator 编写 TensorFlow 程序,您必须执行下列任务:
创建一个或多个输入函数。
定义模型的特征列。
实例化 Estimator,指定特征列和各种超参数。
在 Estimator 对象上调用一个或多个方法,传递适当的输入函数作为数据的来源。
import & FLAGS
FLAGS 与运行参数对应:
1
2
3
4
5
6
7
8
9
10
11
12
13
14python run_squad.py \
--vocab_file=$$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$$BERT_BASE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=/tmp/squad_base/1
2
3
4
5
6
7
8
9
10
11
12from __future__ import absolute_import
...
import collections
...
flags = tf.flags
FLAGS = flags.FLAGS
## Required parameters
flags.DEFINE_string(
"bert_config_file", None,
"The config json file corresponding to the pre-trained BERT model. "
"This specifies the model architecture.")
...validate_flags_or_throw
对传入的部分参数进行检查:
检查指定大小写敏感是否和待加载模型相一致
检查运行模式,train / predict 至少一种,在每种模式下检查输输入文件
检查输入最大长度,不超过最大位置嵌入长度,不小于query最大长度+3
1
2
3
4
5
6
7
8
9
10
11
12def validate_flags_or_throw(bert_config):
# 检查指定大小写敏感是否和待加载模型相一致
tokenization.validate_case_matches_checkpoint(FLAGS.do_lower_case, FLAGS.init_checkpoint)
# 检查运行模式,train / predict 至少一种,在每种模式下检查输输入文件
if not FLAGS.do_train and not FLAGS.do_predict:
if FLAGS.do_train and not FLAGS.train_file:
if FLAGS.do_predict and not FLAGS.predict_file:
raise ValueError(...)
# 检查输入最大长度,不超过最大位置嵌入长度,不小于query最大长度+3
if FLAGS.max_seq_length > bert_config.max_position_embeddings:
if FLAGS.max_seq_length <= FLAGS.max_query_length + 3: # [cls]...[sep]...[sep] 占用三个位置
raise ValueError(...)_compute_softmax
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def _compute_softmax(scores):
"""Compute softmax probability over raw logits."""
...
max_score = None
for score in scores:
if max_score is None or score > max_score:
max_score = score
exp_scores = []
total_sum = 0.0
for score in scores:
x = math.exp(score - max_score) # 防止溢出
exp_scores.append(x)
total_sum += x
probs = []
for score in exp_scores:
probs.append(score / total_sum)
return probs
Squad输入
SquadExample 类
用于 Squad 任务的单个 example,主要包含四部分
context: doc_tokens
id: qas_id
question: question_text
answer: orig_answer_text / start_position / end_position / is_impossible
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class SquadExample(object):
# 对于 answer 不存在的 example,start_position = end_position = -1
def __init__(self,
qas_id,
question_text,
doc_tokens,
orig_answer_text=None,
start_position=None,
end_position=None,
is_impossible=False):
self.qas_id = qas_id
...
# 用于显示的方法
def __str__(self):
return self.__repr__()
def __repr__(self):
s = ""
s += "qas_id: %s" % (tokenization.printable_text(self.qas_id))
...
return sInputFeatures 类
定义输入特征集合数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class InputFeatures(object):
"""A single set of features of data."""
def __init__(self,
unique_id,
example_index,
doc_span_index,
tokens,
token_to_orig_map,
token_is_max_context,
input_ids,
input_mask,
segment_ids,
start_position=None,
end_position=None,
is_impossible=None):
self.unique_id = unique_id
...read_squad_examples
从 .json 格式文件读取输入,解析成 SquadExample 结构
处理流程:load_json 文件 -> 使用 whitespace 来对 context 分词得到 doc_tokens,并构建char到word的映射关系 -> 解析道 qas_id 和 question_text -> 处理 answer,得到 orig_answer_text / start_position / end_position / is_impossible -> SquadExample 结构
- 这时候 start_position 和 end_position 已经是 词级别的了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83def read_squad_examples(input_file, is_training):
"""Read a SQuAD json file into a list of SquadExample."""
with tf.gfile.Open(input_file, "r") as reader:
input_data = json.load(reader)["data"] # dict{"data":..., "version":...}
def is_whitespace(c): # 疑问:ord(c) == 0x202F 和 tokenization.whitespace_tokenize 存在不一致,不会有问题?
if c == " " or c == "\t" or c == "\r" or c == "\n" or ord(c) == 0x202F: # ord(c) 返回字符c的unicode数值,0x202F 表示 NARROW NO-BREAK SPACE
return True
return False
""" input_data 数据结构
- input_data: [{},...,{}]
- 'title': str
- 'paragraphs': [{},...,{}]
- 'context': str
- 'qas': [{},...,{}]
- 'id': str
- 'question': str
- 'answers': [{}] # __len__ = 1
- 'answer_start': int
- 'text': 'str
"""
examples = []
for entry in input_data:
for paragraph in entry["paragraphs"]:
# 处理 context
paragraph_text = paragraph["context"]
doc_tokens = [] # 一个 paragraph["context"] 中的所有 tokens
char_to_word_offset = [] # 每个字符属于第几个 token
prev_is_whitespace = True
# 以 whitespace 为 context 分词
for c in paragraph_text:
if is_whitespace(c): # whitespace 不保存,用来做 tokenize
prev_is_whitespace = True
else:
if prev_is_whitespace: # whitespace 后面是一个新的 token
doc_tokens.append(c)
else:
doc_tokens[-1] += c # 加入到当前 token
prev_is_whitespace = False
char_to_word_offset.append(len(doc_tokens) - 1) # 当前字符属于第几个 token
# 处理 question 和 answer
for qa in paragraph["qas"]:
qas_id = qa["id"]
question_text = qa["question"]
start_position = None # answer 的开始位置
end_position = None # answer 的结束位置
orig_answer_text = None # 原始答案text
is_impossible = False # 对于squad 2.0,存在没有 answer 的问题
if is_training: # 在 predict 阶段,json 文件中没有 answer
if FLAGS.version_2_with_negative:
is_impossible = qa["is_impossible"]
if (len(qa["answers"]) != 1) and (not is_impossible): # 有 answer 的问题唯一解
raise ValueError(
"For training, each question should have exactly 1 answer.")
if not is_impossible: # 有 answer
answer = qa["answers"][0] # 唯一解
orig_answer_text = answer["text"]
answer_offset = answer["answer_start"] # 在 context 中 answer 的 char 级别的 offset
answer_length = len(orig_answer_text) # answer 覆盖的 char 数目
start_position = char_to_word_offset[answer_offset] # char 级别的 offset 转换成 tokens 中的位置
end_position = char_to_word_offset[answer_offset + answer_length - 1]
# 去除可能由编码问题导致 answer 不能在原文找到
actual_text = " ".join(
doc_tokens[start_position:(end_position + 1)])
cleaned_answer_text = " ".join(
tokenization.whitespace_tokenize(orig_answer_text))
if actual_text.find(cleaned_answer_text) == -1:
tf.logging.warning(...)
continue
else: # 没有 answer 的问题,特殊处理
start_position = -1
end_position = -1
orig_answer_text = ""
example = SquadExample(...)
examples.append(example)
return examplesconvert_examples_to_features
将 SquadExample 解析成 一个或多个 InputFeatures
流程:unique_id,example_index -> 对 question_text 分词得到 query_tokens -> 对 doc_tokens 进一步分词得到 all_doc_tokens,并建立两种 tokens 之间的映射关系 -> 更新 answer 在 all_doc_tokens 中的 tok_start_position 和 tok_start_position -> 使用滑动窗口机制处理 all_doc_tokens,每个 doc_span = [[‘CLS’] query_tokens [‘SEP’] doc_span_text [‘SEP’]] -> 对其 answer 在当前 doc_span 中的起始位置 start_position 和 start_position -> InputFeatures 结构 -> 通过 FeatureWriter 写入到 TFRecord 文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143def convert_examples_to_features(examples, tokenizer, max_seq_length,
doc_stride, max_query_length, is_training,
output_fn):
unique_id = 1000000000
for (example_index, example) in enumerate(examples):
# question_text 分词,使用 FullTokenizer.tokenize
query_tokens = tokenizer.tokenize(example.question_text)
if len(query_tokens) > max_query_length:
query_tokens = query_tokens[0:max_query_length]
# FullTokenizer分词后的token在对应的 example.doc_tokens 里面的索引
# 样例:<class 'list'>: [0, 0, 0, 1, 2, 3, 4, 4, ...]
tok_to_orig_index = []
# tok_to_orig_index 的逆,样例:<class 'list'>: [0, 3, 4, 5, ...]
orig_to_tok_index = []
all_doc_tokens = []
for (i, token) in enumerate(example.doc_tokens):
orig_to_tok_index.append(len(all_doc_tokens))
sub_tokens = tokenizer.tokenize(token)
for sub_token in sub_tokens:
tok_to_orig_index.append(i)
all_doc_tokens.append(sub_token)
tok_start_position = None
tok_end_position = None
if is_training and example.is_impossible: # squad v2.0
tok_start_position = -1
tok_end_position = -1
if is_training and not example.is_impossible:
tok_start_position = orig_to_tok_index[example.start_position]
# 例如:ori[end_position] = "unaffable", tok = [..., "un", "##aff", "##able", ...]
# orig_to_tok_index[end_position] 位置在 tok 中对应的是 "un"
# orig_to_tok_index[end_position + 1] - 1 位置在 tok 中对应的是 "##able"
if example.end_position < len(example.doc_tokens) - 1:
tok_end_position = orig_to_tok_index[example.end_position + 1] - 1
# 如果是 ori 中最后一个 token
else:
tok_end_position = len(all_doc_tokens) - 1
# 得到更精准的 answer 的始末位置
(tok_start_position, tok_end_position) = _improve_answer_span(
all_doc_tokens, tok_start_position, tok_end_position, tokenizer,
example.orig_answer_text)
# The -3 accounts for [CLS], [SEP] and [SEP]
max_tokens_for_doc = max_seq_length - len(query_tokens) - 3
# 为了处理超长的文本,使用 滑动窗口 机制
# 每次滑动 doc_stride 的长度,窗口区间为 min(length, max_tokens_for_doc)
# 相邻的 doc_span 之间会有重叠
_DocSpan = collections.namedtuple("DocSpan", ["start", "length"])
doc_spans = []
start_offset = 0
while start_offset < len(all_doc_tokens):
length = len(all_doc_tokens) - start_offset # 剩余未划分成 doc_span 的 tokens 长度
if length > max_tokens_for_doc:
length = max_tokens_for_doc
doc_spans.append(_DocSpan(start=start_offset, length=length))
if start_offset + length == len(all_doc_tokens):
break
start_offset += min(length, doc_stride)
# 对于每个窗口 doc_span,构建拼接的输入 [['CLS'] query_tokens ['SEP'] doc_span_text ['SEP']]
for (doc_span_index, doc_span) in enumerate(doc_spans):
tokens = []
token_to_orig_map = {}
token_is_max_context = {}
segment_ids = []
# '[CLS]' query '[SEP]'
tokens.append("[CLS]")
segment_ids.append(0)
for token in query_tokens:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
for i in range(doc_span.length):
split_token_index = doc_span.start + i # 当前 token 在 all_doc_tokens[] 中的位置
token_to_orig_map[len(tokens)] = tok_to_orig_index[split_token_index]
is_max_context = _check_is_max_context(doc_spans, doc_span_index,
split_token_index)
token_is_max_context[len(tokens)] = is_max_context # 当前 span 是否是当前 token 的最佳 context
tokens.append(all_doc_tokens[split_token_index])
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# mask=1 表示真实 token,需要被 attend 到
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
start_position = None
end_position = None
if is_training and not example.is_impossible:
# For training, if our document chunk does not contain an annotation
# we throw it out, since there is nothing to predict.
doc_start = doc_span.start
doc_end = doc_span.start + doc_span.length - 1
out_of_span = False
# answer 没有被完整包含在当前 span 中
# 会不会 answer 在相邻 doc_span 中都恰好没有完全包含??
# 应该需要 doc_stride << max_tokens_for_doc
# 例如:answer = [token1 token2 token3]
# 当前的span: [... token1 token2] token3 token4...
# 下一个span: ... token1 [token2 token3 token4...] ...
if not (tok_start_position >= doc_start and
tok_end_position <= doc_end):
out_of_span = True
if out_of_span:
start_position = 0
end_position = 0
else:
doc_offset = len(query_tokens) + 2 # '[CLS]' query '[SEP]'
start_position = tok_start_position - doc_start + doc_offset # 在当前拼接的输入中的位置
end_position = tok_end_position - doc_start + doc_offset
if is_training and example.is_impossible: # squad v2.0
start_position = 0
end_position = 0
if example_index < 20:
tf.logging.info(...)
feature = InputFeatures(...)
# 回调函数,通过 FeatureWriter 写入到 TFRecord 文件中
output_fn(feature)
unique_id += 1_improve_answer_span
经过 WordPiece 分词后,可以得到更精准的答案起始位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def _improve_answer_span(doc_tokens, input_start, input_end, tokenizer,
orig_answer_text):
"""Returns tokenized answer spans that better match the annotated answer."""
# Question: What year was John Smith born?
# Context: The leader was John Smith (1895-1943).
# Answer: 1895
# orig_answer_text 可能只是Context中 token 的一部分,经过 WordPiece 分词后,可以有更精准的位置
tok_answer_text = " ".join(tokenizer.tokenize(orig_answer_text))
for new_start in range(input_start, input_end + 1):
for new_end in range(input_end, new_start - 1, -1):
text_span = " ".join(doc_tokens[new_start:(new_end + 1)])
if text_span == tok_answer_text:
return (new_start, new_end)
return (input_start, input_end)FeatureWriter
将 InputFeature 写入到 TFRecords 文件,需要将每一个样本数据封装为tf.train.Example格式,再将Example逐个写入文件。
tf.train.Feature()的参数是BytesList, FloatList, Int64List三种。
tf.train.Features: 它的参数是一个字典,k-v对中 v 的类型是Feature,对应每一个字段。
流程:将每一个字段映射 Feature -> 多个Feature组成Features -> 将其封装为 tf.train.Example 就可以写入 tfrecords二进制文件了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class FeatureWriter(object):
"""Writes InputFeature to TF example file."""
def __init__(self, filename, is_training):
self.filename = filename
self.is_training = is_training
self.num_features = 0
self._writer = tf.python_io.TFRecordWriter(filename) # 将 records 写入到 TFRecords 文件
# 将 InputFeature 解析成 tf.train.Example 写入到 tfrecords 文件
def process_feature(self, feature):
"""Write a InputFeature to the TFRecordWriter as a tf.train.Example."""
self.num_features += 1
def create_int_feature(values):
# 三种基础数据类型:bytes,float,int64
# 对应tf.train中三种类型:BytesList(字符串列表), FloatList(浮点数列表), Int64List(64位整数列表)
feature = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return feature
features = collections.OrderedDict()
features["unique_ids"] = create_int_feature([feature.unique_id])
...
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
self._writer.write(tf_example.SerializeToString())
def close(self):
self._writer.close()_check_is_max_context
检查当前 doc_span 是不是某个 position 的左&右context 最丰富的 span
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def _check_is_max_context(doc_spans, cur_span_index, position):
"""Check if this is the 'max context' doc span for the token."""
# 用来给当前 position 选择出 左&右context 最丰富的 span
# Because of the sliding window approach taken to scoring documents, a single
# token can appear in multiple documents. E.g.
# Doc: the man went to the store and bought a gallon of milk
# Span A: the man went to the
# Span B: to the store and bought
# Span C: and bought a gallon of
# ...
#
# Now the word 'bought' will have two scores from spans B and C. We only
# want to consider the score with "maximum context", which we define as
# the *minimum* of its left and right context (the *sum* of left and
# right context will always be the same, of course).
#
# In the example the maximum context for 'bought' would be span C since
# it has 1 left context and 3 right context, while span B has 4 left context
# and 0 right context.
best_score = None
best_span_index = None
for (span_index, doc_span) in enumerate(doc_spans):
end = doc_span.start + doc_span.length - 1
if position < doc_span.start:
continue
if position > end:
continue
num_left_context = position - doc_span.start
num_right_context = end - position
# 加平滑项,倾向于选择长 span,context 更丰富
score = min(num_left_context, num_right_context) + 0.01 * doc_span.length
if best_score is None or score > best_score:
best_score = score
best_span_index = span_index
return cur_span_index == best_span_index
Estimator
create_model
创建序列分类模型
引入 start vector ,paragraph 中第 个位置是 start_position 的概率为 ,end_position 同理。
本函数使用 BERT 最后 hidden 层输出,映射为 start vector 和 end vector 两个向量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
use_one_hot_embeddings):
model = modeling.BertModel(...)
final_hidden = model.get_sequence_output() # BERT 最后 hidden 层输出
final_hidden_shape = modeling.get_shape_list(final_hidden, expected_rank=3)
(batch_size, seq_length, hidden_size) = final_hidden_shape
output_weights = tf.get_variable(
"cls/squad/output_weights", [2, hidden_size], # start vector 和 end vector 两个向量
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"cls/squad/output_bias", [2], initializer=tf.zeros_initializer())
final_hidden_matrix = tf.reshape(final_hidden,
[batch_size * seq_length, hidden_size])
logits = tf.matmul(final_hidden_matrix, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias) # [batch_size * seq_length, 2]
logits = tf.reshape(logits, [batch_size, seq_length, 2]) # [batch_size, seq_length, 2]
logits = tf.transpose(logits, [2, 0, 1]) # # [2, batch_size * seq_length]
# start vector: [batch_size * seq_length]
# end vector: [batch_size * seq_length]
unstacked_logits = tf.unstack(logits, axis=0)
(start_logits, end_logits) = (unstacked_logits[0], unstacked_logits[1])
return (start_logits, end_logits)
model_fn_builder
创建模型函数
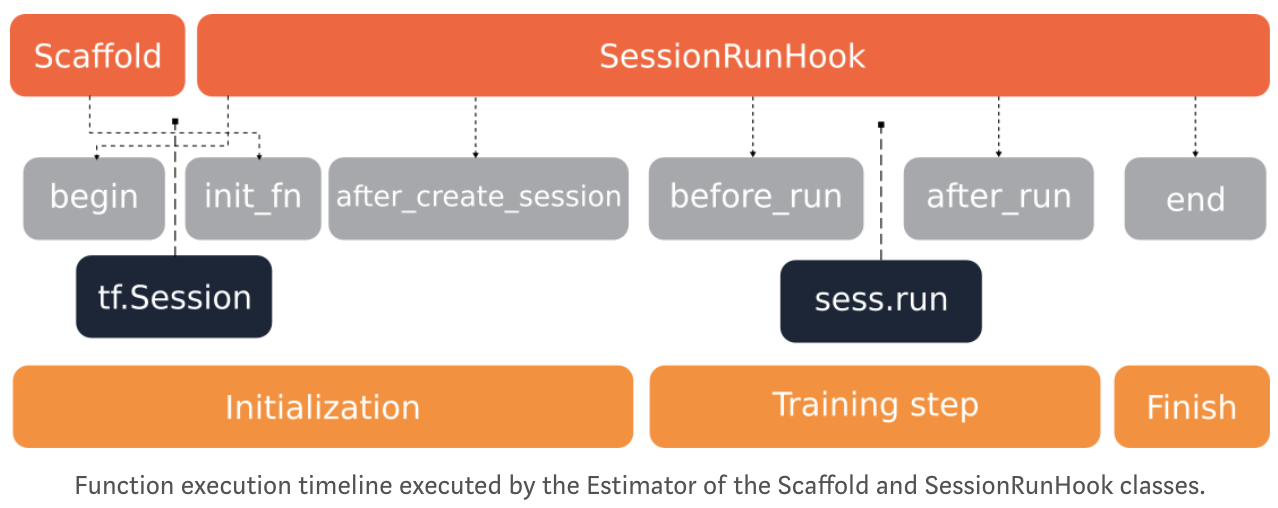
👀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109def model_fn_builder(bert_config,
init_checkpoint,
learning_rate,
num_train_steps,
num_warmup_steps,
use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
# 前两个参数是从输入函数中返回的特征和标签batch
# mode 参数表示调用程序是请求训练、预测还是评估
# params: 额外参数。调用程序可以将 params 传递给 Estimator 的构造函数。
# 传递给构造函数的所有 params 转而又传递给 model_fn。
"""
def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys, see below
params): # Additional configuration
当有人调用 train()、evaluate() 或 predict() 时,Estimator 框架会 调用模型函数 并将 mode 参数设置为如下所示的值:
Estimator方法 Estimator 模式 返回
train() ModeKeys.TRAIN EstimatorSpec(mode, loss, train_op)
evaluate() ModeKeys.EVAL EstimatorSpec(mode, loss, eval_metric_ops)
predict() ModeKeys.PREDICT EstimatorSpec(mode, predictions)
对于每个 mode 值,都必须返回 tf.estimator.EstimatorSpec 的一个实例,其中包含调用程序所需的信息。
EstimatorSpec:Ops and objects returned from a model_fn and passed to an Estimator
EstimatorSpec **fully** defines the model to be run by an Estimator.
tf.summary.scalar 会在 TRAIN 和 EVAL 模式下向 TensorBoard 提供准确率
"""
# 根据运行模式,创建并返回不同的 EstimatorSpec
def model_fn(features, labels, mode, params): # params example: {'batch_size': 12, 'use_tpu': False}
"""The `model_fn` for TPUEstimator."""
...
unique_ids = features["unique_ids"] # Tensor("IteratorGetNext:5", shape=(12,), dtype=int32)
input_ids = features["input_ids"] # Tensor("IteratorGetNext:1", shape=(12, 384), dtype=int32)
input_mask = features["input_mask"] # Tensor("IteratorGetNext:2", shape=(12, 384), dtype=int32)
segment_ids = features["segment_ids"] # Tensor("IteratorGetNext:3", shape=(12, 384), dtype=int32)
is_training = (mode == tf.estimator.ModeKeys.TRAIN) # 运行模式
(start_logits, end_logits) = create_model(...)
tvars = tf.trainable_variables()
initialized_variable_names = {}
# 通过 tf.Scaffold 自定义 variable initialization
# 作为 Scaffold 参数传给 EstimatorSpec 的构造函数
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
# Replaces tf.Variable initializers so they load from a checkpoint file.
tf.train.init_from_checkpoint(init_checkpoint, assignment_map) #
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
...
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN:
seq_length = modeling.get_shape_list(input_ids)[1]
# 使用 cross-entropy / negative-log-likelihood 计算 loss
def compute_loss(logits, positions):
one_hot_positions = tf.one_hot(
positions, depth=seq_length, dtype=tf.float32)
log_probs = tf.nn.log_softmax(logits, axis=-1)
loss = -tf.reduce_mean(
tf.reduce_sum(one_hot_positions * log_probs, axis=-1))
return loss
start_positions = features["start_positions"]
end_positions = features["end_positions"]
# 计算 loss
start_loss = compute_loss(start_logits, start_positions)
end_loss = compute_loss(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2.0
# Creates an optimizer training op
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.PREDICT: # 预测
predictions = {
"unique_ids": unique_ids,
"start_logits": start_logits,
"end_logits": end_logits,
}
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions=predictions, scaffold_fn=scaffold_fn)
else:
raise ValueError(
"Only TRAIN and PREDICT modes are supported: %s" % (mode))
return output_spec
return model_fninput_fn_builder
创建输入函数
Tensorflow 的 Dataset API 包含下列类:
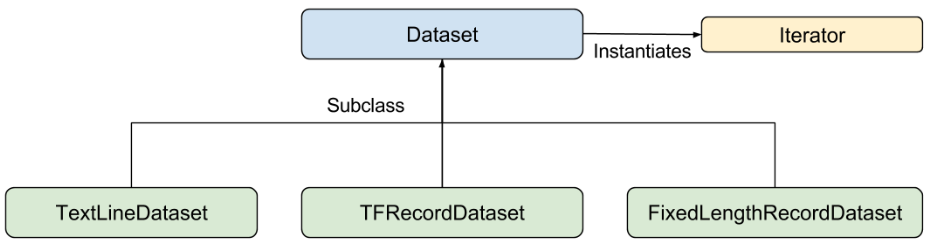
Dataset- 包含创建和转换数据集的方法的基类。您还可以通过该类从内存中的数据或 Python 生成器初始化数据集。TextLineDataset- 从文本文件中读取行。
TFRecordDataset- 从 TFRecord 文件中读取记录。(我们这里使用)FixedLengthRecordDataset- 从二进制文件中读取具有固定大小的记录。
Iterator- 提供一次访问一个数据集元素的方法创建输入函数流程:
定义待map的 features -> 实例化TFRecordDataset对象,从TFRecord 文件中读取记录 -> repeat & shuffle -> 将 record map到 features,构建batch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44def input_fn_builder(input_file, seq_length, is_training, drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
name_to_features = {
# tf.FixedLenFeature: Configuration for parsing a fixed-length input feature.
# 返回一个定长的tensor
"unique_ids": tf.FixedLenFeature([], tf.int64),
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.int64),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
}
if is_training:
name_to_features["start_positions"] = tf.FixedLenFeature([], tf.int64)
name_to_features["end_positions"] = tf.FixedLenFeature([], tf.int64)
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
# 返回一个 feature keys 到 `Tensor`的 dict
example = tf.parse_single_example(record, name_to_features)
... # tf.int64 -> tf.int32,实现TPU 兼容
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
# For training, we want a lot of parallel reading and shuffling.
# For eval, we want no shuffling and parallel reading doesn't matter.
d = tf.data.TFRecordDataset(input_file) # 从 TFRecord 文件中读取记录
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
# tf.data.Dataset.apply(transformation_func)
# 将用户自定义的转换函数应用于当前数据集
# tf.contrib.data.map_and_batch 对数据集的 batch_size 个连续元素,先 map 后 batch
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder)) # 默认 False,最后一个 batch 长度小于 batch_size 不丢弃
return d
return input_fn
write_predictions
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173def write_predictions(all_examples, all_features, all_results, n_best_size,
max_answer_length, do_lower_case, output_prediction_file,
output_nbest_file, output_null_log_odds_file):
"""Write final predictions to the json file and log-odds of null if needed."""
example_index_to_features = collections.defaultdict(list)
for feature in all_features: # InputFeatures
example_index_to_features[feature.example_index].append(feature)
unique_id_to_result = {}
for result in all_results: # RawResult(unique_id,start_logits,end_logits)
unique_id_to_result[result.unique_id] = result
_PrelimPrediction = collections.namedtuple(
"PrelimPrediction",
["feature_index", "start_index", "end_index", "start_logit", "end_logit"])
all_predictions = collections.OrderedDict()
all_nbest_json = collections.OrderedDict()
scores_diff_json = collections.OrderedDict()
for (example_index, example) in enumerate(all_examples): # SquadExample
features = example_index_to_features[example_index] # 当前 SquadExample 对应的 features
prelim_predictions = []
# 跟踪 answer 不存在的时候的最小 socre
score_null = 1000000 # large and positive
min_null_feature_index = 0 # the paragraph slice with min mull score
null_start_logit = 0 # the start logit at the slice with min null score
null_end_logit = 0 # the end logit at the slice with min null score
for (feature_index, feature) in enumerate(features): # 一个 SquadExample 可以解析出一个或多个 features
result = unique_id_to_result[feature.unique_id]
start_indexes = _get_best_indexes(result.start_logits, n_best_size)
end_indexes = _get_best_indexes(result.end_logits, n_best_size)
# if we could have irrelevant answers, get the min score of irrelevant
if FLAGS.version_2_with_negative:
# 对于 v2,answer 不存在时,start_position = end_position = 0
feature_null_score = result.start_logits[0] + result.end_logits[0]
if feature_null_score < score_null:
score_null = feature_null_score
min_null_feature_index = feature_index
null_start_logit = result.start_logits[0]
null_end_logit = result.end_logits[0]
for start_index in start_indexes:
for end_index in end_indexes:
# 丢弃无效的 index 的情况:
# 预测到了 pad 位置、预测到了 非context 的位置
if start_index >= len(feature.tokens):
continue
if end_index >= len(feature.tokens):
continue
if start_index not in feature.token_to_orig_map:
continue
if end_index not in feature.token_to_orig_map:
continue
# 当前span不是 start_index 的最大上下文 (?为什么不处理end_index)
if not feature.token_is_max_context.get(start_index, False):
continue
if end_index < start_index:
continue
length = end_index - start_index + 1
if length > max_answer_length:
continue
prelim_predictions.append( # 暂存可能的 [start, end] 组合
_PrelimPrediction(...))
if FLAGS.version_2_with_negative:
prelim_predictions.append(
_PrelimPrediction(
feature_index=min_null_feature_index,
start_index=0,
end_index=0,
start_logit=null_start_logit,
end_logit=null_end_logit))
# 对所有可能的 [start, end] 组合排序
# logit 的大小会用于 softmax 计算概率
# e^start_logit * e^end_logit = e^(start_logit+end_logit)
prelim_predictions = sorted(
prelim_predictions,
key=lambda x: (x.start_logit + x.end_logit),
reverse=True)
_NbestPrediction = collections.namedtuple( # pylint: disable=invalid-name
"NbestPrediction", ["text", "start_logit", "end_logit"])
seen_predictions = {}
nbest = []
# 选出前 n_best_size 得分的 [start, end] 组合
for pred in prelim_predictions:
if len(nbest) >= n_best_size:
break
feature = features[pred.feature_index]
# 对于 non-null 的 answer,从 tokens 恢复出 text
if pred.start_index > 0: # this is a non-null prediction
tok_tokens = feature.tokens[pred.start_index:(pred.end_index + 1)]
orig_doc_start = feature.token_to_orig_map[pred.start_index]
orig_doc_end = feature.token_to_orig_map[pred.end_index]
orig_tokens = example.doc_tokens[orig_doc_start:(orig_doc_end + 1)]
tok_text = " ".join(tok_tokens)
# De-tokenize WordPieces 得到的是 BasicTokenizer 分词后的格式
tok_text = tok_text.replace(" ##", "")
tok_text = tok_text.replace("##", "")
# Clean whitespace
tok_text = tok_text.strip()
tok_text = " ".join(tok_text.split()) # wordpiece tokens 恢复出的 answer
orig_text = " ".join(orig_tokens) # 原文的 answer,如:'(NFL) for the 2015 season. The American'
final_text = get_final_text(tok_text, orig_text, do_lower_case)
if final_text in seen_predictions:
continue
seen_predictions[final_text] = True
# 对于 null, answer =""
else:
final_text = ""
seen_predictions[final_text] = True
nbest.append(
_NbestPrediction(
text=final_text,
start_logit=pred.start_logit,
end_logit=pred.end_logit))
# if we didn't inlude the empty option in the n-best, inlcude it
if FLAGS.version_2_with_negative:
if "" not in seen_predictions:
nbest.append(
_NbestPrediction(
text="", start_logit=null_start_logit,
end_logit=null_end_logit))
# In very rare edge cases we could have no valid predictions. So we
# just create a nonce prediction in this case to avoid failure.
if not nbest:
nbest.append(
_NbestPrediction(text="empty", start_logit=0.0, end_logit=0.0))
assert len(nbest) >= 1
# 计算每个 [start, end] 组合的概率
total_scores = []
best_non_null_entry = None
for entry in nbest:
total_scores.append(entry.start_logit + entry.end_logit)
if not best_non_null_entry:
if entry.text:
best_non_null_entry = entry
probs = _compute_softmax(total_scores)
...
# 对于 v1,始终存在 answer,直接将得分最高的作为输出
if not FLAGS.version_2_with_negative:
all_predictions[example.qas_id] = nbest_json[0]["text"]
# 对于 v2,可能存在找不到 answer,根据以下公式是否成立来确定输出
# null score - the score of best non-null > threshold
else:
score_diff = score_null - best_non_null_entry.start_logit - (
best_non_null_entry.end_logit)
scores_diff_json[example.qas_id] = score_diff
if score_diff > FLAGS.null_score_diff_threshold:
all_predictions[example.qas_id] = ""
else:
all_predictions[example.qas_id] = best_non_null_entry.text
all_nbest_json[example.qas_id] = nbest_json
... 写入文件get_final_text
我们可以同时得到两种 answer 表示,一种是原文中的 tokens 直接恢复出来的 orig_text,另一种是 wordPiece 的 subtokens 可以恢复出的更精确的 pred_text。 如果 pred_text 能在 orig_text 中定位/对齐到,那么输出更精确的 pred_text。如果因为分词过程带来的差异,导致pred_text 在原文中恢复不出来,那么直接输出 pred_text。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109def get_final_text(pred_text, orig_text, do_lower_case):
"""Project the tokenized prediction back to the original text."""
# When we created the data, we kept track of the alignment between original
# (whitespace tokenized) tokens and our WordPiece tokenized tokens. So
# now `orig_text` contains the span of our original text corresponding to the
# span that we predicted.
#
# However, `orig_text` may contain extra characters that we don't want in
# our prediction.
#
# For example, let's say:
# pred_text = steve smith
# orig_text = Steve Smith's
#
# We don't want to return `orig_text` because it contains the extra "'s".
#
# We don't want to return `pred_text` because it's already been normalized
# (the SQuAD eval script also does punctuation stripping/lower casing but
# our tokenizer does additional normalization like stripping accent
# characters).
#
# What we really want to return is "Steve Smith".
#
# Therefore, we have to apply a semi-complicated alignment heruistic between
# `pred_text` and `orig_text` to get a character-to-charcter alignment. This
# can fail in certain cases in which case we just return `orig_text`.
# 将字符串 s 中的空格去掉得到 ns,并且建立 ns 索引到 s 索引的映射
def _strip_spaces(text):
ns_chars = []
ns_to_s_map = collections.OrderedDict()
for (i, c) in enumerate(text):
if c == " ":
continue
ns_to_s_map[len(ns_chars)] = i
ns_chars.append(c)
ns_text = "".join(ns_chars)
return (ns_text, ns_to_s_map)
# We first tokenize `orig_text`, strip whitespace from the result
# and `pred_text`, and check if they are the same length. If they are
# NOT the same length, the heuristic has failed. If they are the same
# length, we assume the characters are one-to-one aligned.
tokenizer = tokenization.BasicTokenizer(do_lower_case=do_lower_case)
# 举例:orig_text = '(NFL) for the 2015 season. The American'
# tok_text = '( nfl ) for the 2015 season . the american'
# pred_text = ') for the 2015 season . the american'
tok_text = " ".join(tokenizer.tokenize(orig_text))
start_position = tok_text.find(pred_text)
# pred_text 不在 BasicTokenizer 处理后的 orig_text 中
# pred_text 中有 '[UNK]'这样的情况需要返回 orig_text
# 举例:orig_text = '(/tᵻˈnɒfərə/; singular ctenophore,'
# tok_text = '( / tᵻˈnɒfərə / ; singular ctenophore ,'
# pred_text = '[UNK] / ; singular cteno'
if start_position == -1:
if FLAGS.verbose_logging:
tf.logging.info(
"Unable to find text: '%s' in '%s'" % (pred_text, orig_text))
return orig_text
end_position = start_position + len(pred_text) - 1
(orig_ns_text, orig_ns_to_s_map) = _strip_spaces(orig_text) # 例 '(NFL)forthe2015season.TheAmerican'
(tok_ns_text, tok_ns_to_s_map) = _strip_spaces(tok_text) # 例 '(nfl)forthe2015season.theamerican'
# BasicTokenizer 会去掉一些音节之类的符号,导致 orig_ns_text 和 tok_ns_text 不对齐
# 举例:
# orig_ns_text = 'dust".)ItofferedaclassiccurriculumontheEnglishuniversitymodel—manyleadersinthecolonyhadattendedtheUniversityofCambridge—butconformedPuritanism.'
# tok_ns_text = 'dust".)itofferedaclassiccurriculumontheenglishuniversitymodel—manyleadersinthecolonyhadattendedtheuniversityofcambridge—butconformedpuritanism.'
if len(orig_ns_text) != len(tok_ns_text):
if FLAGS.verbose_logging:
tf.logging.info("Length not equal after stripping spaces: '%s' vs '%s'",
orig_ns_text, tok_ns_text)
return orig_text
# 将 pred_text 定位/对齐到 orig_text 中
# We then project the characters in `pred_text` back to `orig_text` using
# the character-to-character alignment.
tok_s_to_ns_map = {}
for (i, tok_index) in six.iteritems(tok_ns_to_s_map):
tok_s_to_ns_map[tok_index] = i
orig_start_position = None
if start_position in tok_s_to_ns_map:
ns_start_position = tok_s_to_ns_map[start_position]
if ns_start_position in orig_ns_to_s_map:
orig_start_position = orig_ns_to_s_map[ns_start_position]
if orig_start_position is None:
if FLAGS.verbose_logging:
tf.logging.info("Couldn't map start position")
return orig_text
orig_end_position = None
if end_position in tok_s_to_ns_map:
ns_end_position = tok_s_to_ns_map[end_position]
if ns_end_position in orig_ns_to_s_map:
orig_end_position = orig_ns_to_s_map[ns_end_position]
if orig_end_position is None:
if FLAGS.verbose_logging:
tf.logging.info("Couldn't map end position")
return orig_text
output_text = orig_text[orig_start_position:(orig_end_position + 1)]
return output_text_get_best_indexes
将一个 logits 按照逆序排序,取出前 n 个值的索引
1
2
3
4
5
6
7
8
9
10def _get_best_indexes(logits, n_best_size):
"""Get the n-best logits from a list."""
index_and_score = sorted(enumerate(logits), key=lambda x: x[1], reverse=True)
best_indexes = []
for i in range(len(index_and_score)):
if i >= n_best_size:
break
best_indexes.append(index_and_score[i][0])
return best_indexesmain
主程序😄 终于到终点啦,不过这也是运行的起点~
流程:加载并检查模型配置 -> 创建Tokenizer -> 配置TPU
- train: -> 读取训练输入文件并shuffle -> 创建模型函数 -> 创建 estimator -> 处理输入并创建输入函数 -> estimator.train
- predict: -> 读取预测输入文件 -> 创建模型函数 -> 创建 estimator -> 处理输入并创建输入函数 -> estimator.predict -> output
- (为了方便对比,稍微调整了下 predict 的过程)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file)
validate_flags_or_throw(bert_config)
tf.gfile.MakeDirs(FLAGS.output_dir)
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
... tpu 相关 ...
run_config = tf.contrib.tpu.RunConfig(...) # 必须将 tf.contrib.tpu.RunConfig 传递给构造函数
train_examples = None
num_train_steps = None
num_warmup_steps = None
if FLAGS.do_train:
train_examples = read_squad_examples(
input_file=FLAGS.train_file, is_training=True)
num_train_steps = int(len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs)
num_warmup_steps = int(num_train_steps * FLAGS.warmup_proportion) # 和学习率有关
# Pre-shuffle the input to avoid having to make a very large shuffle
# buffer in in the `input_fn`.
rng = random.Random(12345)
rng.shuffle(train_examples)
model_fn = model_fn_builder(
bert_config=bert_config,
init_checkpoint=FLAGS.init_checkpoint,
learning_rate=FLAGS.learning_rate,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
use_tpu=FLAGS.use_tpu,
use_one_hot_embeddings=FLAGS.use_tpu)
# If TPU is not available, this will fall back to normal Estimator on CPU or GPU.
# TPUEstimator 类与 Estimator 类有所不同。
# 要维护可在 CPU/GPU 或 Cloud TPU 上运行的模型,最简单的方式是将模型的推理阶段(从输入到预测)定义在 model_fn 之外。
# 然后,确保 Estimator 设置和 model_fn 的单独实现,二者均包含此推理步骤。
# 在本地计算机上使用 tf.contrib.tpu.TPUEstimator 所需的更改相对较少。将构造函数中的 use_tpu 参数设为 False,并将
# tf.contrib.tpu.RunConfig 以 config 参数的形式传递。
estimator = tf.contrib.tpu.TPUEstimator(
use_tpu=FLAGS.use_tpu,
model_fn=model_fn,
config=run_config,
train_batch_size=FLAGS.train_batch_size,
predict_batch_size=FLAGS.predict_batch_size)
if FLAGS.do_train:
# We write to a temporary file to avoid storing very large constant tensors
# in memory.
train_writer = FeatureWriter(
filename=os.path.join(FLAGS.output_dir, "train.tf_record"),
is_training=True)
convert_examples_to_features(
examples=train_examples,
tokenizer=tokenizer,
max_seq_length=FLAGS.max_seq_length,
doc_stride=FLAGS.doc_stride,
max_query_length=FLAGS.max_query_length,
is_training=True,
output_fn=train_writer.process_feature)
train_writer.close()
tf.logging.info("***** Running training *****")
...
del train_examples
train_input_fn = input_fn_builder(
input_file=train_writer.filename,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
# 每当有人调用 Estimator 的 train、evaluate 或 predict 方法时,就会调用模型函数。
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
if FLAGS.do_predict:
eval_examples = read_squad_examples(
input_file=FLAGS.predict_file, is_training=False)
eval_writer = FeatureWriter(
filename=os.path.join(FLAGS.output_dir, "eval.tf_record"),
is_training=False)
eval_features = []
def append_feature(feature):
eval_features.append(feature) #
eval_writer.process_feature(feature)
convert_examples_to_features(..., output_fn=append_feature)
eval_writer.close()
tf.logging.info("***** Running predictions *****")
...
all_results = []
predict_input_fn = input_fn_builder(...)
# If running eval on the TPU, you will need to specify the number of
# steps.
all_results = []
for result in estimator.predict(
predict_input_fn, yield_single_examples=True):
if len(all_results) % 1000 == 0:
tf.logging.info("Processing example: %d" % (len(all_results)))
unique_id = int(result["unique_ids"])
start_logits = [float(x) for x in result["start_logits"].flat]
end_logits = [float(x) for x in result["end_logits"].flat]
all_results.append(
RawResult(
unique_id=unique_id,
start_logits=start_logits,
end_logits=end_logits))
output_prediction_file = os.path.join(FLAGS.output_dir, "predictions.json")
output_nbest_file = os.path.join(FLAGS.output_dir, "nbest_predictions.json")
output_null_log_odds_file = os.path.join(FLAGS.output_dir, "null_odds.json")
write_predictions(eval_examples, eval_features, all_results,
FLAGS.n_best_size, FLAGS.max_answer_length,
FLAGS.do_lower_case, output_prediction_file,
output_nbest_file, output_null_log_odds_file)